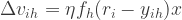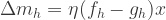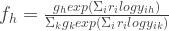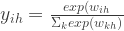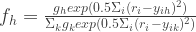Recently, I’ve been working on classification of very high dimensional (input dimension ~150.000) and sparse data as a continuation of Artificial Neural Networks course project I’ve finished last semester. I’m currently experimenting with Mixture of Experts architecture to see if it produces better classification rates. As you can see in my last post, first I have implemented MoE model in MATLAB but I needed an implementation that performs faster so I ported my MATLAB code to C with a few additions. Since my focus was on sparse data where most of the input values are zero, I have implemented separate, optimized functions for training and testing with sparse input data.
Below you can see sample code to initialize, train and test MoE model with synthetic data I have generated for classification.
// ClassifySyntheticData.c
//
// Copyright 2011 Goker Erdogan <goker@goker-laptop>
//
// This program is free software; you can redistribute it and/or modify
// it under the terms of the GNU General Public License as published by
// the Free Software Foundation; either version 2 of the License, or
// (at your option) any later version.
//
// This program is distributed in the hope that it will be useful,
// but WITHOUT ANY WARRANTY; without even the implied warranty of
// MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
// GNU General Public License for more details.
//
// You should have received a copy of the GNU General Public License
// along with this program; if not, write to the Free Software
// Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston,
// MA 02110-1301, USA.
#include "MoE.h"
#include <stdio.h>
int main( int argc, char **argv)
{
int inputDim = 2;
int outputDim = 2;
int expertCount = 2;
int trainCount = 600;
int testCount = 400;
int iterCount = 5;
MoEType *moe = InitializeMoE( inputDim, outputDim, expertCount, COMPETITIVE, 0.1, 0.99 );
double x[2];
double rd;
int r;
FILE *tfp = fopen("trainMoE.txt","r");
FILE *vfp = fopen("testMoE.txt","r");
int i = 0;
int n;
int rc;
int misclassified = 0;
while( i < iterCount )
{
i++;
for ( n = 0; n < trainCount; n++ )
{
fscanf(tfp, "%lf %lf %lf\n", &x[0], &x[1], &rd);
r = (int)rd;
TrainOnlineD(moe, x, r, 0);
}
misclassified = 0;
for ( n = 0; n < testCount; n++ )
{
fscanf(vfp, "%lf %lf %lf\n", &x[0], &x[1], &rd);
r = (int)rd;
rc = TestSample(moe, x);
if ( rc != r )
{
misclassified++;
}
}
printf("Iteration %d Classification Rate: %f\n", i, (testCount - misclassified) / (double)testCount);
}
fclose(tfp);
fclose(vfp);
FreeMoE(moe);
return 0;
}
You can find data structures and functions for MoE model, synthetic classification dataset and sample code given above in the source code which you can download here.
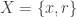 where
where  is a
is a 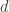 x
x 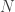 matrix where each row vector contains input values and
matrix where each row vector contains input values and  is a
is a 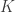 x
x 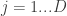 inputs,
inputs, 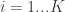 outputs,
outputs,  experts,
experts, 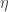 learning rate
learning rate
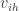
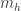 is a D-vector.
is a D-vector.

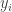 are converted to posterior probabilities through softmax function.
are converted to posterior probabilities through softmax function. 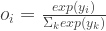
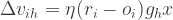
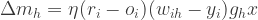
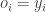 for regression )
for regression )